| DeepSeek,就像一颗投入平静湖面的巨石,激起了千层浪。卡帕西对它震惊不已,山姆奥特曼也忍不住发出阴阳怪气的评论,国外媒体更是纷纷报道,称其为神秘的东方魔法。它究竟是什么来历。
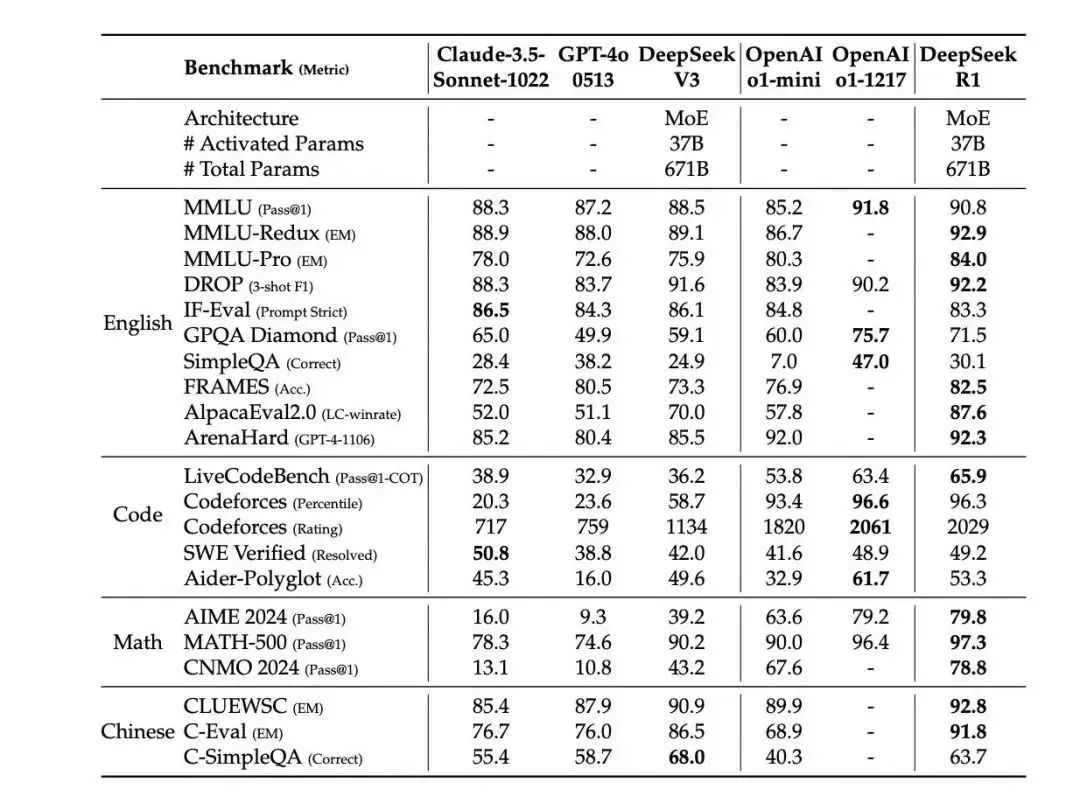
DeepSeek来者何人 要知道,训练像 ChatGPT 这样的大模型,通常需要至少 100 张英伟达 A100 显卡,成本之高让许多企业望而却步。而 DeepSeekv3 却打破了这一常规,仅用 557 万美元的成本,就实现了 OpenAI、Google、Meta 需要上亿美元才能达到的效果。这个成本大约是 Llama3.1 的 1/10,GPT-4o 的 1/20。在如此低的成本下,DeepSeek 还成功登顶开源模型的巅峰,超越了 Llama3.1 和千问 2.5,甚至赶超了闭源的昂贵模型 Claude3.5 和 GPT4o。这不禁让人好奇,DeepSeek 到底有何过人之处? DeepSeek 能够取得如此成就,离不开其强大的技术支撑。它的背后是国产顶级量化基金幻方,这家规模曾迈过千亿大关的量化私募,在 2023 年 4 月成立了全资子公司,正式投身 AI 赛道。早在 2019 年,幻方就开始集卡,2021 年更是投入 10 亿用于这一项目。在 GPT3.5 出来之前,幻方就已经做好了充分的准备。在当时能够拿出万卡的公司屈指可数,商汤、百度、腾讯、字节、阿里,然后就是幻方。 “黑科技”加持 DeepSeekv3 采用了 MoE 架构,也就是混合专家模型。我们把DeepSeek想象成一个工厂,几百个专家模型组成一个 “超级团队”,每个专家都有自己的 “拿手好戏”,有的擅长编程,有的擅长数学。遇到问题时,谁合适谁上,这效率简直 “爆表”!但这还不算完,DeepSeek 还有一堆 “秘密武器”:MLA 多层注意力架构和 FP8 混合精度训练框架,这俩就像是给模型训练 “减肥” 和 “加速” 的神器,让训练过程又快又省力。DualPipe 跨节点通信、无辅助损失的负载均衡策略、跨节点全对全通信内核等技术,更是把每一个计算资源都利用到了极致,就像把每一个 “小工” 都安排得明明白白,压榨到底。 DeepSeek的MTP 技术,一次能预测多个连续的 token,这就好比别人一次只能看一步,而它能看几步,效率和效果都提升了一个档次。再加上 DeepSeek-R1 蒸馏技术,从 R1 模型中提取推理模式和解题策略来微调主干模型,几乎就是自我进化。
AI界“拼多多” Llama3.1 需要 16000 张 H100 GPU 训练好几个月,而 DeepSeek 仅用 2048 张阉割版 H800 就训练了两个月,计算量仅为 Llama3.1 的 1/8。这就好比别人开的是 “豪华跑车”,而 DeepSeek 开的是 “经济适用型小轿车”,但速度和性能却不相上下。更夸张的是推理成本,某些大模型的会员费用高达 20 美元,还限额使用,而 DeepSeek 的 API 每百万 token 只需 1块钱。 别看价格低,DeepSeek编程能力和数学能力比肩 Claude3.5 和 GPT4o,在多任务和复杂问题上的表现更是逼近 Claude 的水平。这背后,得益于三个原因:一是模型参数量足够大,DeepSeekv3 拥有 671B 的参数量,比 Llama3.1 的 405B 多出 200 多,这就像盖房子用的砖更多,房子自然更牢固;二是数据质量高,DeepSeek 采用了 14.8T token 的精挑细选数据,这就好比给模型喂的都是 “超级食材”;三是适当偏科,通过 MTP 技术和 DeepSeek-R1 蒸馏,实现了自我进化和能力提升,就像学生在某些科目上特别擅长,整体成绩也跟着水涨船高。
普通人用DeepSeek DeepSeek 的出现,让中国制造在 AI 界扬眉吐气了一把。它用事实证明,即使没有顶级 GPU,也能训练出超越其他模型的优秀大模型。不过,也有人酸溜溜地说 DeepSeek 只是复制了 ChatGPT 的工作方式,没有新技术,对此,我们不予置评。 说了那么多DeepSeek的强大,我们普通人到底能用来干嘛呢?
课程福利
|